若能知道HTTP协议的工作原理,就能理解浏览器和服务器是怎么对话的。为什么会有GET,POST,Cookie,URL,状态码?甚至你以后抓包、调试、写代码、做安全分析都会轻松很多。
一,我们先看下HTTP协议的工作流程:
第一步:你在浏览器里输入一个网址,例如www.baidu.com,然后按下回车。
首先,这个网址叫URL,全称是:统一资源定位符,它包含4个部分,第一部分叫做协议,也就是头部的“HTTP://”,告诉浏览器要用HTTP这个协议连接服务器,现在几乎都是https://协议,意思是连接是加密的,数据更加安全,后面我们在讲解HTTP和HTTPS的区别。第二部分是域名,例如baidu.com,就是网站在服务器上的地址。第三部分和第四部分是路径和资源,可以理解为文件夹和文件,加在一起,就是指向服务器上的某个内容或者文件夹。
第二步:按下回车后,浏览器通过DNS系统(域名系统),把baidu.com这个域名转换成和这个域名绑定的服务器上的IP地址。为了加快找到IP地址的速度,DNS的信息会被层层缓存:浏览器会先查查自己有没有解析访问且缓存过这个IP地址,没有的话就去问操作系统,还是没有的话,就去公网上问DNS服务器,一层一层找,直到找到。一旦找到IP地址,浏览器就用这个IP地址和服务器建立TCP连接,这个过程需要所谓的“三次握手”。一旦建立了TCP连接,浏览器就可以和服务器进行HTTP通信了。具体的会在TCP的工作原理里讲。
第三步:浏览器通过这个TCP连接发送HTTP请求,服务器接收到请求后,会返回响应,比如HTML页面。浏览器拿到响应后,开始渲染页面。如果页面中还引用了其他资源,比如图片,JS文件,浏览器就会重复这3个步骤,直到完成整个请求和响应。如果响应回来的是一个文件,浏览器就会提示你下载。
第四步:断开TCP连接。一旦服务器返回了数据,就要关闭这个TCP连接了,除非你配置了keep-alive保持连接,否则就直接关闭连接了,执行TCP四次挥手。
二,了解了整个过程,那就来看看HTTP的请求和响应的具体工作内容
HTTP的全称是Hypertext Transfer Protocol,超文本传输协议。超文本也就是包含了链接、能跳来跳去的文本,也就是我们看到的网页。传输是负责把数据从一端搬到另一端。协议是双方事先约定好的通信规则,所以HTTP的核心工作,就是在浏览器客户端和服务器之间按照事先约定好的通信规则可靠地传输网页、图片、视频等一切你能看到的内容。
浏览器客户端和服务器的对话遵循一个极其经典的模型:请求与响应。
请求和响应都是以HTTP报文的格式发送,HTTP 报文 是 HTTP 协议交互的信息载体,分为两种类型:请求报文(由客户端发送)和响应报文(由服务器返回)。报文是纯文本格式(HTTP/1.1 和早期版本),由 ASCII 字符组成,便于阅读和调试。
请求:你在浏览器输入网址,敲下回车,浏览器就会按照HTTP的格式封装一个请求,发向服务器,这个请求里会写明我要用什么方法,比如GET方法,拿哪个页面,以及我用的浏览器的一些信息。
响应:服务器收到请求后,开始查找资源,然后封装一个响应,回传给浏览器,这个响应里会包含请求成功还是失败,返回的内容是什么,以及内容的类型等,这就是一次完整的HTTP事务。你滚动页面,点击链接,背后就是无数次这样的请求响应,不断地循环。
(一)HTTP请求报文(Request Message)
HTTP请求是纯文本的,由四部分组成:
第一部分叫请求行,例如GET/index.html,HTTP/1.1,它告诉服务器,我想访问这个index.html文件,我使用的方法是GET,我用的HTTP版本是1.1。
第二部分叫请求头,比如Host, UserAgent, Accept,cookie等等,这些头部就像是信封上的说明,告诉服务器你是什么浏览器,你能接受什么格式的文件,你需要携带哪些cookie。
第三部分是一个空行,表示头部结束。空行必须有,用于分隔头部和主体。没有主体时,直接以空行结束。
第四部分是请求体,也就是Body,多数情况下,GET请求没有body(也叫主体),而Post,PUT等方法会携带数据,比如表单信息、json、图片、甚至是文件,它们就会有body。
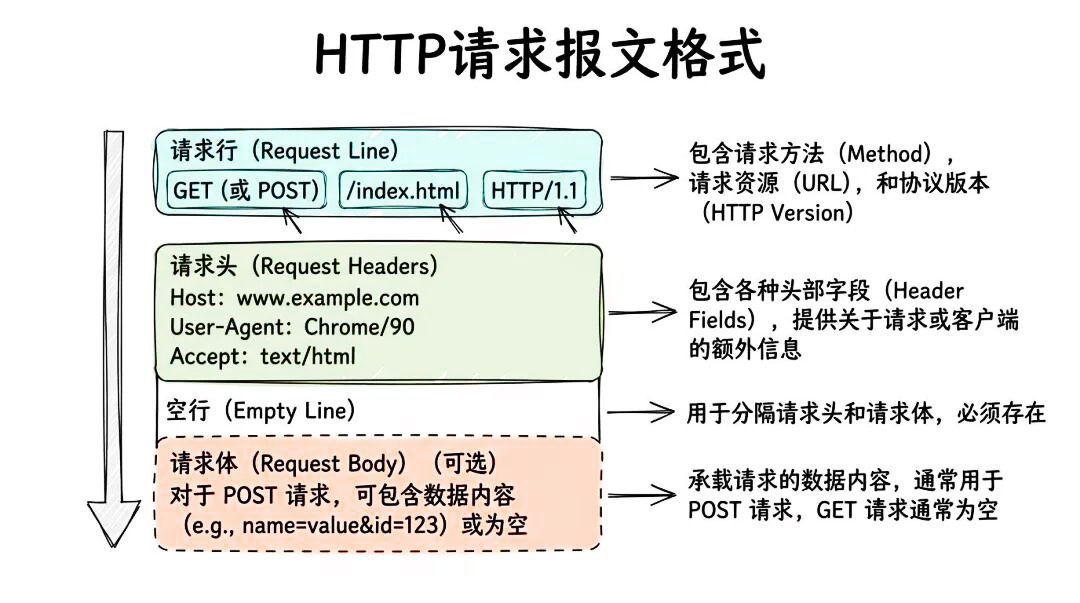

示例(Get请求,无主体):
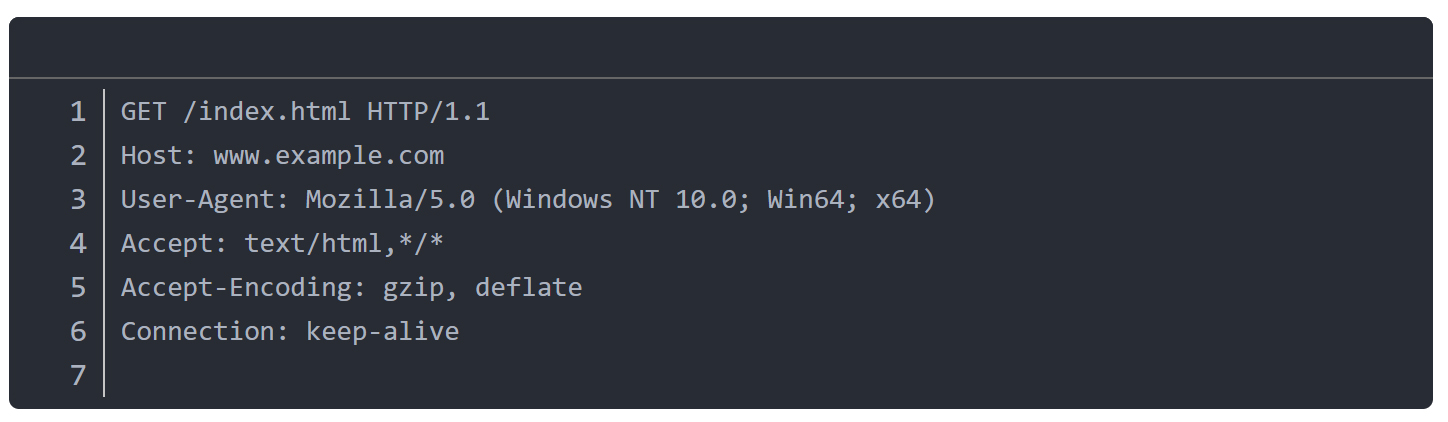
示例(POST请求,有主体):
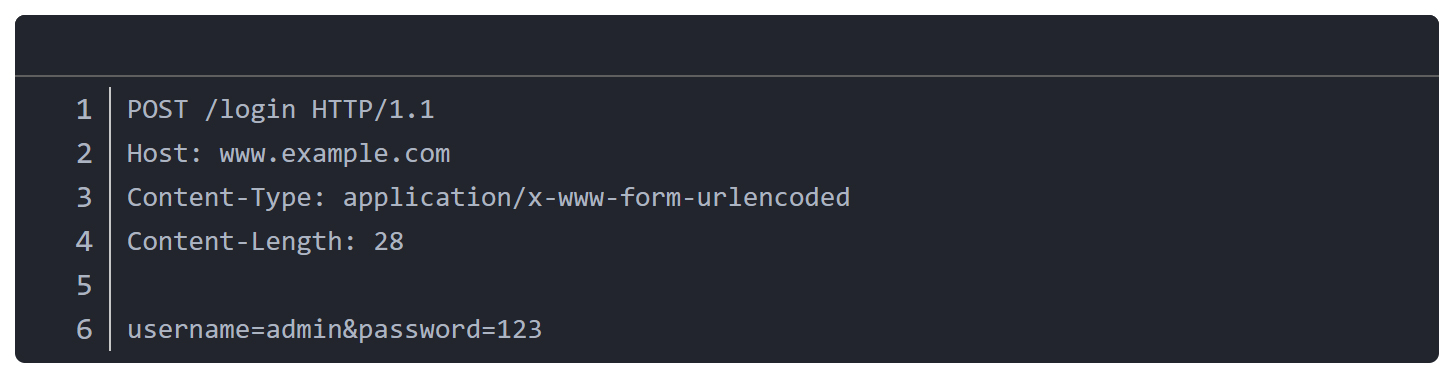
HTTP的请求方法,表示对资源的操作。常见方法如下表:
(二)HTTP响应报文(Response Message)好,请求发出去之后,就是服务器响应。HTTP的响应格式和请求非常像,也分为四段。
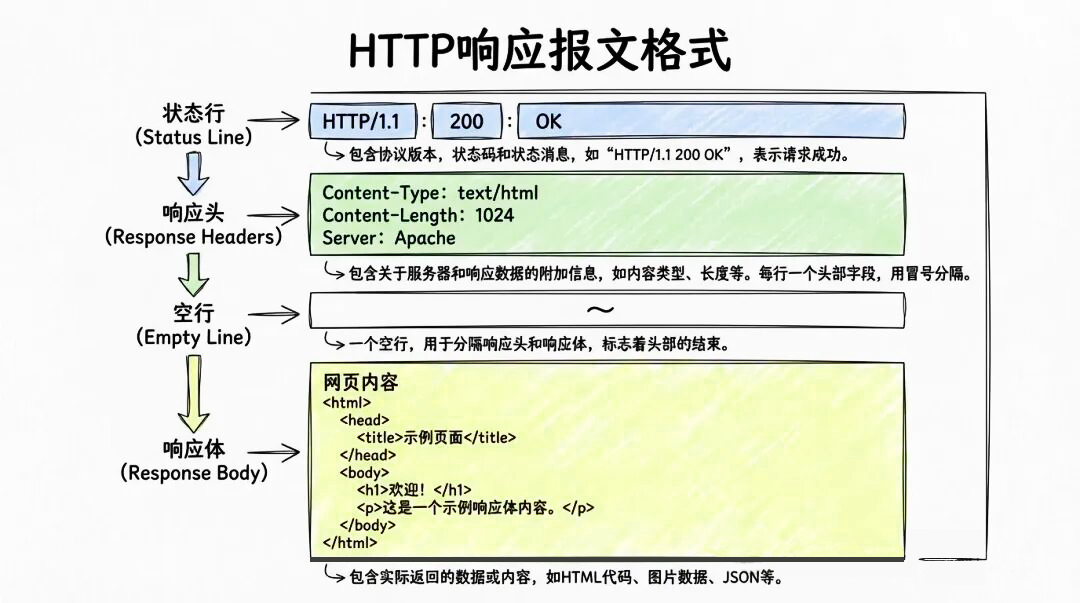
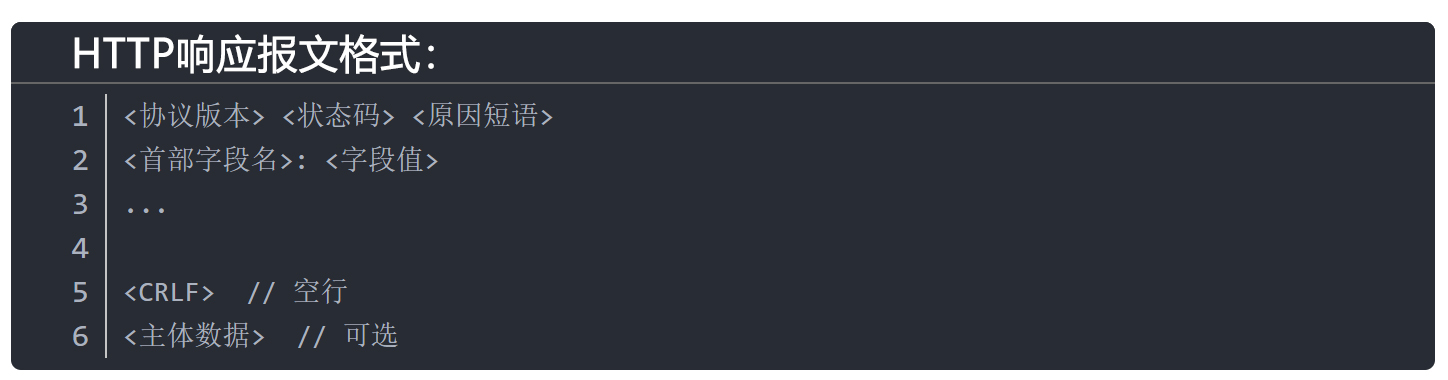


第一部分叫状态行,比如 HTTP/1.1 200 OK。这里的状态码非常重要。200 表示成功;301 和 302 表示重定向;403 表示无权访问;404 表示资源不存在;500 则表示服务器内部出了问题。
第二部分叫响应头。比如ContentType, ContentLength,Set-Cookie,这些内容告诉浏览器返回的数据是什么格式,长度是多少,有没有新的Cookie要存下来。
第三部分是一个空行,分隔头部和体。
第四部分是响应体,也就是你真正想要的内容,例如HTML文本、CSS、JS、图片、视频,或者返回给前端的JSON数据。以上请求和响应报文格式就是HTTP最基础、最核心的结构。
常见的响应头:

三:下面说的是几个重要概念,能更清楚地了解HTTP:
第一个关键点:HTTP是无状态协议。什么意思?就是每个请求都是独立的,服务器不会记得你是谁,浏览器必须依靠cookie或者Token,让服务器在每次请求里重新知道你是同一个用户,比如登陆之后查看订单,服务器就是靠cookie或者token来识别你仍然是登陆状态。
第二个关键点:HTTP 有多种方法。最常见的是 GET 和 POST。GET 通常用来获取数据,参数一般写在 URL 后面。而 POST 用来提交数据,比如登录、注册、上传文件,它需要在 Body 中携带数据。除此之外,还有 PUT、DELETE、HEAD 等方法,不过在前端普通业务中用得不多。
第三个关键点:Content-Type。HTTP 可以传输各种格式的数据,因此必须用 Content-Type 声明内容格式。常见的有 text/html,表示 HTML 文本;application/json,表示 JSON 数据;multipart/form-data,表示文件上传。你上传图片、视频的时候,就是通过 multipart 格式把文件切成多个部分传输。
第四个关键点:长连接与短连接。早期的 HTTP 1.0 默认是短连接,请求完成后就断开。HTTP 1.1 引入了 Keep-Alive,使得连接可以复用,大大提升性能。到了 HTTP 2,不仅可以复用连接,还能并发传输多个流,更快、更高效。
第五个关键点:HTTP 与 HTTPS 的区别。HTTPS 是在 HTTP 外面套了一层 TLS 加密。HTTP 明文传输,容易被窃听和篡改,而 HTTPS 加密传输,不仅保证数据无法被偷看,还能确保服务器身份真实可靠。现在几乎所有网站都强制迁移到 HTTPS,就是因为安全性提升巨大。
有2个密码学中的黄金法则:
1,公钥密码学。想象一下你有一把很特别的锁,你可以随便复制很多份这把锁给全世界任何人,这就是公钥,但是开这把锁的钥匙,全世界只有一把,而且只在你手里,这就是私钥,所以任何人想给你寄个秘密盒子,有可以用你的公开锁把它锁上,一旦锁上,除了你手上那把独一无二的私钥,谁都打不开,这样一来,就算是在一个谁都能偷听的网络上,也能保证信息的机密性了。
2,数字签名。一个绝对无法伪造的个人印章,或者是数字指纹,你用你的私钥给一个文件盖个章,那任何人拿到这份文件,都可以用你的公钥来验证一下,看下这个章是不是你盖的,这就解决了身份认证的问题,说明是真的人在和服务器对话。
然后去看看浏览器和网站是怎么建立起安全连接的,这个过程叫TLS握手,这个握手分5步:
第一步:浏览器发送HTTP请求。
第二步:服务器收到请求,它说,好呀,这是我的身份证,也是证书,这个证书里就包含了它的公钥。
第三步:这是最关键的一步,你的浏览器拿到这个身份证之后,不是马上就信了,它会仔细检查这个证书是不是真的,是不是由权威机构签发的。这个权威机构是一个大家都信得过的中间人,这个中间人就是证书办法机构,简称CA,一个网站想要拿到CA证书,就必须通过严谨的身份验证,YouTube会自己先生成一堆公钥和私钥,然后把自己的公钥和一些身份信息打包做成一个证书签名请求,也就是CS2,然后把这个CS2提交给大家都信任的CA,比如谷歌自己的CA,CA收到请求后,会去做尽职调查,合适YouTube的身份,确认无误后,CA会用自己的私钥在YouTube的请求上盖个章,也就进行数字签名,为YouTube的身份和公钥做了背书,一份受信任的证书就诞生了。CA机制怎么防止坏人冒充的?黑客可以伪造一个证书,说我就是YouTube.com,但是关键问题是这个证书是谁签发的,只有是全球公认的权威的CA,浏览器才会认可。一些浏览器在出厂的时候,脑子里就已经预装了一份可信任机构白名单,它看到是谷歌CA签发的证书就会说,哦,这我认识,我信任它。看到不认识的签发机构,就会立马给你一个大大的安全警告。这就是所谓的信任链。
第四步:一旦确认对方身份没问题,你的浏览器就会现场生成一个新的临时的秘密暗号,叫会话密钥,案后浏览器用拿到的youtube的公钥,把这个新暗号加密,再发回去给YouTube,
第五步:YouTube用自己的私钥解开这个包裹,拿到了那个秘密暗号,现在浏览器和YouTube双方手里,都有了同一个谁也不知道的秘密暗号,接下来,它们就可以用这个暗号进行高效的加密通讯了。一条安全通道就这么建立起来了。就算有个黑客在中间全程偷听,他只能截获一堆被公钥加密过的乱码,因为他没有YouTube的私钥,他就根本解不开浏览器发的那个秘密暗号,拿不到这个暗号,那后面所有的对方他都听不懂